

Your HVAC tech just wrapped an emergency call at 2 AM in a basement with zero signal. Your landscaping crew spent the entire day working rural properties forty miles from the nearest cell tower. Your delivery drivers keep hitting dead zones between distribution centers.
And somehow, you need accurate time data for tomorrow's payroll run.
Most offline time tracking field workers scenarios end the same way — scrambled text messages at midnight, paper timesheets stuffed in truck glove boxes, and supervisors spending Sunday mornings manually reconstructing who worked where. The data eventually makes it back, but by then you've already processed payroll with estimates, dealt with three overtime disputes, and explained to finance why labor costs spiked 18% without warning. The real operational damage happens in those hours between capture and reconciliation. Missing punches turn into compliance violations, buddy punching slips through undetected, and a simple connectivity gap becomes a $4,000 payroll correction.
The buffered capture pattern most field operations miss
Construction sites, agricultural operations, and utility maintenance crews face a fundamental mismatch — workers need to log time precisely when they have the worst connectivity. The standard approach treats this as a technology problem. Buy better devices, boost cellular plans, install signal boosters. But that misses the point entirely.
Watch what happens when field techs lose signal mid-shift. They don't immediately switch to paper backup. They assume the app will sync later, keep working, then forget what time they started that second service call. By evening, they're reconstructing their day from memory, rounding everything to the nearest hour because who remembers starting a job at 2:47 PM three jobs ago?
The buffered capture pattern flips this sequence. Instead of hoping for eventual sync, you design assuming zero connectivity and treat any signal as a bonus. Capture happens continuously on-device with local validation, while sync becomes a scheduled operational event rather than a background hope.
Picture how this works for a 12-person roofing crew. Each morning, their devices pull down that day's job assignments, client addresses, and estimated hours. Throughout the day, every clock-in, break, and job completion gets timestamped locally with GPS coordinates. The app validates entries against expected patterns — it flags when someone logs 16 straight hours or when GPS shows them 50 miles from their assigned site.
The data stays buffered on-device until hitting designated sync windows. Not random connectivity moments, but specific operational checkpoints where sync becomes part of the workflow. Lunch break at the main office. End-of-day vehicle return. Morning crew meetings. These natural gathering points guarantee at least one solid sync opportunity daily.
The validation layer prevents the chaos of bulk uploads. When that roofing crew's data finally syncs at 5 PM, the system already knows Tom's 14-hour entry conflicts with mandatory break requirements. It knows Sarah's GPS showed her at two sites simultaneously. It catches these before they hit payroll, before they become compliance issues, before they need manual correction.
This diagram illustrates the on-device capture, local validation, designated sync windows, and post-sync exception detection working together.
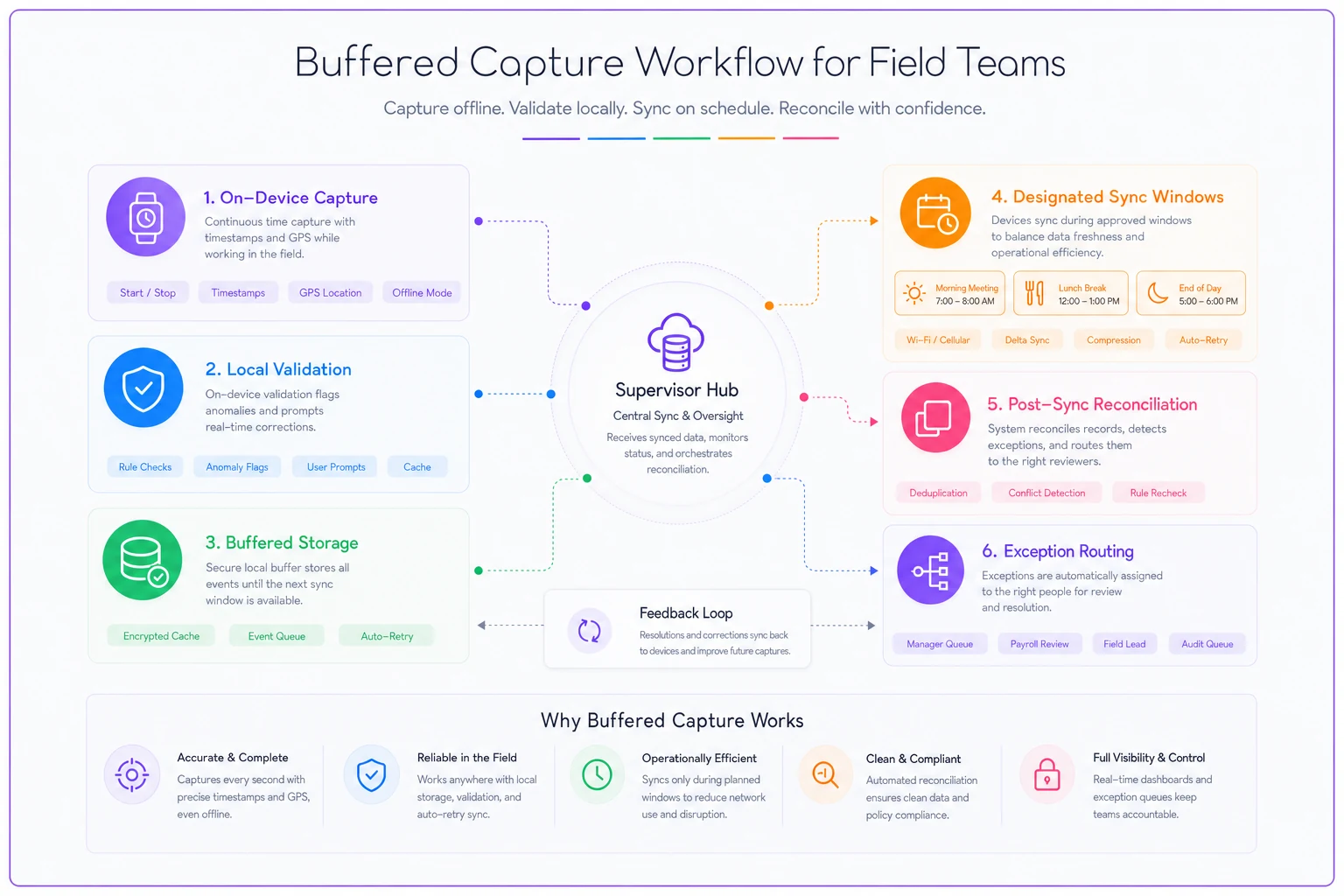
When the system is designed this way, sync becomes a predictable operational event instead of a hope, and exceptions are surfaced with context rather than as bulk problems for payroll to fix.
Supervisor sync windows that actually match field reality
Traditional time tracking assumes constant connectivity and treats supervisors as occasional reviewers. Field operations flip both assumptions. Supervisors become the primary sync points, and their review happens in structured windows rather than random spot-checks.
Accurate time tracking made effortless.
GoTimio empowers your team to log, monitor, and manage work hours seamlessly.
- Real-time time tracking
- Automated timesheet approvals
- Payroll and billing integration
No credit card required
Consider a municipal utilities crew maintaining water infrastructure across rural counties. Their supervisor drives between sites daily, physically present at each location for 20-30 minutes. That's the sync window. Not some arbitrary 6 PM deadline, but the actual moment when supervisor and crew occupy the same space.
The supervisor's device acts as a mobile hub. When they arrive on-site, crew devices automatically detect and establish local connection — no cellular needed. The past 8 hours of buffered entries sync to the supervisor's device in seconds. More importantly, exceptions surface immediately. Missing meal breaks, unsigned safety checklists, GPS anomalies that need explanation.
This proximity-based sync creates natural accountability. The foreman can ask Marcus why his GPS shows him 10 miles off-site during lunch. They can verify with the crew that everyone actually worked the overtime showing in their logs. These conversations happen while memories are fresh, while workers are present, while corrections take seconds instead of emails.
Supervisor sync windows serve another purpose — they become commitment points. Once the supervisor validates and locks that day's entries, they can't be silently edited later. This protects both parties. Workers can't claim unpaid hours weeks later, and companies can't retroactively adjust logs to avoid overtime. The sync window creates a bilateral agreement, documented and timestamped.
Some operations layer multiple sync tiers. Crew leads sync with their 3-4 direct reports every few hours. Site supervisors sync with crew leads at shift change. Regional managers pull aggregated data during their weekly site visits. Each tier catches different exception types, from individual timestamp errors to site-wide pattern violations.
Nightly reconciliation as operational discipline, not IT maintenance
Most businesses treat reconciliation as error correction — fix what broke today before tomorrow's reports. But disconnected field teams need reconciliation as proactive pattern management. It's not about fixing individual timestamps. It's about catching systemic issues before they cascade into payroll disasters or compliance violations.
The nightly reconciliation routine starts with pattern detection. A proper system identifies anomalies without human review. It knows your electrical contractors average 8.5 hours on residential calls but 11 hours on commercial retrofits. When tonight's sync shows three techs logging 14 hours on standard residential work, that's an exception requiring explanation, not just overtime requiring approval.
Effective nightly reconciliation for a 50-person landscaping company operating across three counties looks like this:
| Stage | Time | Details |
|---|---|---|
| Stage 1: Automated collection (10 PM - 11 PM) | 10 PM - 11 PM | All supervisor devices sync to central system. Buffered data from crews who never found signal gets pulled from supervisor devices. The system assembles a complete picture of the day's operations, even from crews who worked entirely offline. |
| Stage 2: Pattern analysis (11 PM - 12 AM) | 11 PM - 12 AM | Algorithm compares today's data against historical patterns. It flags unusual travel times between sites, suspicious clusters of identical timestamps, missing entries for scheduled workers. But it also identifies efficiency gains — crews completing routes 20% faster, new techs matching senior productivity levels. |
| Stage 3: Exception queuing (12 AM - 1 AM) | 12 AM - 1 AM | Issues get categorized and routed. Potential buddy punching goes to senior supervisors. Missing meal breaks go to compliance. Unusual overtime patterns go to operations. Each exception includes context — not just "John worked 15 hours" but "John worked 15 hours, 40% above his average, on a site typically requiring 8 hours, with no logged break." |
| Stage 4: Morning resolution (6 AM - 7 AM) | 6 AM - 7 AM | Supervisors arrive to pre-sorted exception queues. They're not hunting through spreadsheets or comparing paper logs. They see exactly what needs attention, with all context readily available. A five-minute review catches what used to take two hours of manual checking. |
The power comes from consistency. Every night, without fail, this routine processes the day's chaos into tomorrow's clarity. Patterns emerge that spot checks would miss. That crew consistently logging extra hours on Thursdays? Turns out they're padding time before their long weekend. The new tech whose hours seem suspicious? Actually just incredibly efficient, completing routes 30% faster than veterans.
Exception handling frameworks that account for messy reality
Field operations generate exceptions constantly. The question isn't whether you'll have exceptions — it's whether your framework can process them without grinding operations to a halt.
Start with exception categories that match operational reality. Not generic "time entry errors" but specific field patterns:
Connectivity exceptions: Worker had no signal for entire shift. Device died mid-day. App crashed and lost four hours of entries. These aren't disciplinary issues, they're operational realities requiring standard handling procedures.
Boundary exceptions: Worker started before scheduled shift to handle emergency. Worked through lunch to meet deadline. Stayed late waiting for parts delivery. These need rapid approval paths, not lengthy justification processes.
Pattern exceptions: Same worker missing punches every Friday. Crew consistently over-hours on specific job types. GPS showing impossible travel speeds between sites. These indicate systematic issues requiring investigation, not individual corrections.
The framework must handle each category differently. Connectivity exceptions get benefit of the doubt — approve the hours, flag for follow-up. Boundary exceptions need context verification — check if customer confirmed emergency, if deadline was real, if parts actually arrived late. Pattern exceptions trigger investigations — not punitive, but operational. Maybe those job types genuinely take longer. Maybe Friday's missing punches correlate with early site dismissals.
Exception authority must match field reality. If your senior field supervisor can approve $50,000 equipment purchases, they can approve overtime exceptions. If your crew lead manages safety compliance, they can validate meal break exceptions. Pushing every exception up to HR or finance creates bottlenecks that encourage workarounds.
The escalation path should follow operational logic:
-
Individual timestamp issues → direct supervisor
-
Pattern violations → site manager
-
Compliance risks → operations director
-
Systemic failures → executive review
Each level has different resolution tools. Supervisors can approve individual adjustments. Site managers can modify site-specific rules. Operations directors can update company-wide policies. This prevents exception handling from becoming a game of approval tag.
Building resilience into offline-dependent operations
The difference between brittle and resilient offline time tracking for field workers comes down to redundancy design. Not technology redundancy — backup servers and failover systems — but operational redundancy that assumes technology will fail at the worst possible moment.
A concrete contractor running six crews across remote development sites builds resilience through overlapping capture methods. Primary: mobile app with offline buffering. Secondary: SMS-based logging to a designated number. Tertiary: physical timesheets in every vehicle. But here's the key — all three methods stay active continuously. Workers log in the app, text their start time, and initial paper logs. This isn't inefficient, it's resilient. When the app database corrupts during an update, SMS logs provide backup. When cell towers go down during storms, paper logs preserve the record.
Standardize SMS numbers and paper log templates across fleets so reconciliation can automatically match redundant inputs quickly.
The reconciliation process expects these overlapping inputs. Instead of treating multiple entries as errors, it uses them for validation. When app and SMS timestamps match within two minutes, that's strong confidence. When paper shows different hours, that triggers investigation. The overlap becomes a feature, not a bug.
AI-powered operational software transforms this redundancy from burden to advantage. Instead of supervisors manually comparing three sources, automated reconciliation runs continuously. It identifies discrepancies in real-time, flags patterns across sources, and builds confidence scores for each entry. That concrete contractor's office manager no longer spends Monday mornings reconciling logs. The system already identified that Tom's app showed 7 AM start, his SMS said 7:15, and his paper log showed 8 AM — flagging it for supervisor verification with all evidence pre-assembled.
Resilience also means graceful degradation. When connectivity drops, functionality reduces but doesn't disappear. Full signal enables real-time GPS tracking, job photos, and customer signatures. Degraded signal still captures timestamps and basic entries. Zero signal maintains local logging with periodic retry. The system never forces workers to stop logging, just adjusts what gets captured based on available resources.
The governance layer that prevents downstream chaos
Time data flows into everything — payroll, billing, compliance, project costing. Without governance, offline capture issues cascade into organization-wide problems. A missed sync becomes a payroll error becomes an employee complaint becomes a labor investigation.
Effective governance starts with data hierarchy. Not all time entries deserve equal trust. Entries with GPS verification, supervisor proximity confirmation, and matching redundant sources get highest confidence. Manually entered corrections three days later get lowest. This hierarchy drives downstream decisions. High-confidence entries flow automatically to payroll. Low-confidence entries require additional validation.
The governance framework needs explicit rules for common scenarios:
Sync delays: If data doesn't sync within 24 hours, supervisor must provide written explanation. After 48 hours, alternative documentation required. After 72 hours, finance gets notified of potential payroll impact.
Correction windows: Workers can adjust their own entries for 4 hours after initial entry. Supervisors can adjust for 24 hours. After that, corrections require documentation and trigger audit trail.
Pattern thresholds: Three missing punches trigger retraining. Five trigger process review. Ten trigger technology assessment. The thresholds prevent individual issues from becoming systematic failures.
But governance really proves its value during exceptions. When a storm knocks out cellular for three days, the framework already defines how to handle mass connectivity failures. When a system update corrupts a week of data, the recovery process is documented and tested. When regulatory audit requests six months of logs, the preservation and export procedures are ready.
Making offline-first sustainable at scale
The challenge with offline time tracking for field workers isn't making it work once — it's maintaining accuracy as you scale from 10 to 100 to 1,000 field workers. What works for a single crew falls apart when applied across regions, time zones, and varying connectivity conditions.
Scale requires architectural decisions that seem like overkill for small operations. Timestamp everything in UTC, even if you only operate in one timezone. Store GPS coordinates for every entry, even if you don't currently use them. Maintain device-specific sync logs, even if you only have 20 devices. These decisions cost nothing at small scale but become impossible retrofits at large scale.
The reconciliation infrastructure must scale horizontally. Not bigger servers processing more data, but distributed processing matching your operational topology. Regional supervisors reconcile regional data. Division managers reconcile divisions. Only aggregated, exception-flagged data flows to central systems. This prevents the 3 AM crisis where someone in corporate IT has to manually process 10,000 field entries because the central reconciliation job failed.
Scaling also exposes the cost of exceptions. When you have 10 workers, manually fixing five missing punches takes 10 minutes. When you have 1,000 workers generating 500 exceptions daily, manual handling becomes impossible. This is where AI automation transforms from nice-to-have to operational necessity. Pattern recognition identifies which exceptions need human review versus automatic resolution. A machine learning model trained on your historical corrections can resolve 80% of standard exceptions automatically, flagging only true anomalies for review.
The communication layer often breaks first at scale. Email notifications work for 10 supervisors. They create chaos for 100. The solution isn't fewer notifications but smarter routing. Supervisors only see exceptions for their direct reports. Regional managers see patterns across their region. Executives see trending metrics and compliance risks. Everyone gets exactly what they need to act, nothing more.
Creating accountability without surveillance
Field workers resist time tracking when it feels like surveillance. They embrace it when it protects their interests — proving overtime worked, documenting difficult conditions, establishing patterns for workers' comp claims.
Workers should see exactly what their supervisors see. Same dashboards, same reports, same exception flags. When a supervisor questions why someone took three hours on a typically two-hour job, the worker can pull up the same GPS data showing the massive traffic delay. This shared visibility transforms time tracking from monitoring to mutual documentation.
The reconciliation process should surface wins, not just violations. That crew that consistently finishes routes early? Recognize it. The tech who never misses a punch despite working the most remote sites? Celebrate it. When workers see the system catching their extra efforts, not just their mistakes, compliance improves dramatically.
But accountability really comes from predictable consequences. Not punishment, but process. Missing punch? Standard correction form. Pattern of violations? Documented retraining. Systematic buddy punching? Progressive discipline. When everyone knows exactly what triggers what response, behavior aligns naturally. The framework removes supervisor discretion from routine violations while preserving it for genuine exceptions.
From reactive scrambles to proactive patterns
Every Sunday night, across thousands of field operations, the same scramble repeats. Supervisors calling workers trying to reconstruct Friday's hours. Payroll processors making educated guesses about missing entries. Finance explaining labor variances based on incomplete data.
But operations running proper offline-first capture patterns tell a different story. Their supervisors spend Sunday evenings with family, knowing Monday's payroll data is already reconciled. Their workers trust that every hour worked gets captured and credited. Their finance teams can actually forecast labor costs because the data flows predictably, accurately, and completely.
The shift from reactive to proactive isn't about better technology or stricter policies. It's about accepting that offline time tracking for field workers isn't an edge case to handle but the primary pattern to design around. When you build assuming disconnection, connectivity becomes a bonus. When you design for exceptions, normal operations feel effortless. When you implement governance before problems arise, crisis management disappears.
The companies getting this right share common patterns. They've stopped fighting connectivity reality and started building around it. They've moved reconciliation from IT maintenance to operational discipline. They've transformed exception handling from punitive process to continuous improvement. Most importantly, they've recognized that time data isn't just about paying workers — it's the foundation for understanding and improving every aspect of field operations. Your field workers are offline right now, still generating time data you need for tomorrow's decisions. The question isn't whether that data will eventually make it back. It's whether your capture patterns, sync windows, and reconciliation routines can transform that inevitable delay from operational chaos into competitive advantage.
Ready to optimize your workforce time management?
Join 2,000+ companies using GoTimio to improve timesheet accuracy, reduce payroll errors, and boost team productivity.